Created Friday 17 April 2026
Some more thoughts about optimal control problems inspired by the CodinGame 2026 winter challenge.
In the challenge, I control multiple robot-snakes who need to eat as many "power sources" as possible. Most of the time, the snakes are independent - and then most of the time each snake's head can just move wherever it wants and the exact shape of the snake is irrelevant. How can we use these simplifications without hurting ourselves too much – that is catching the situations where the simplification is not applicable and taking a more detailed view in those cases?
I want to look at this question through the lenses of a "projection" and an "approximation". A projection reduces a "bigger" optimal control problem to a smaller one - and we know how to solve small optimal control problems using the Bellman equation. An "approximation" reuses our ability to solve one optimal control problem to approach the solution of a different but similar one. But first, we need the notation.
Optimal control problem
An optimal control porblem will be described by:
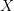 - the set of possible states of the system
- the set of possible states of the system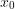 - the initial state
- the initial state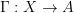 - a set-valued function that for each
- a set-valued function that for each 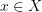 determines the set of all possible controls
determines the set of all possible controls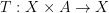 - the transition function, so that the state
- the transition function, so that the state 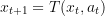 for the control
for the control 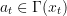
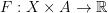 - the reward function. The goal is to maximize
- the reward function. The goal is to maximize
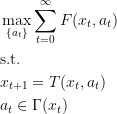
Projection
A projection of an optimal control problem 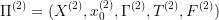 into an optimal control problem
into an optimal control problem 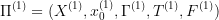 is a pair of functions
is a pair of functions 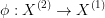 and
and 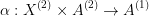 such that
such that
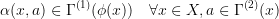
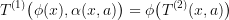
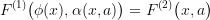
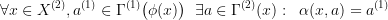
The meaning behind these long formulas is trivial: there is a mapping of states of 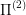 into the states of
into the states of 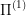 , such that if I am able to solve
, such that if I am able to solve 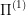 , then the corresponding controls in
, then the corresponding controls in 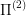 are also optimal for
are also optimal for 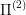 . An example of a projection would be the optimal control problems:
. An example of a projection would be the optimal control problems:
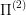 : snake-bot that can pass through itself and is not allowed to fall down
: snake-bot that can pass through itself and is not allowed to fall down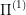 : character-with-a-jet-pack
: character-with-a-jet-pack
Here is how GodinGame describes the rules for the snake-bot:
Each player controls a team of snakebots. On each turn, the snakebots move simultaneously according to the players' commands.
🗺️ Map
The grid is seen from the side, and is made up of platforms. Platforms are impassable cells.
On this grid you may find parts of a snakebot's body and power sources.
🐍 Snakebot
Snakebots are multiple adjacent cell-sized body parts. The first cell being their head.
Snakebots are affected by gravity. Meaning at least one body part must be above something solid or they will fall.
Other snakebots are considered solid, as well as platforms and power sources .
↪️ Movement
Snakebots are perpetually moving, and will on each turn head in the last direction they were facing unless given a new direction to turn by the player.
The starting direction is up.
When moving, a snakebot will advance their head in the direction it is facing, and the rest of its body parts will follow.
[...]
Once movement and removals are resolved, the snakebots all
In our modification of the rules (the "not allowed to fall down" part), if snakebot has to fall, it "is removed" (dies) instead.
For "character-with-a-jet-pack" I imagine the following rules:
The grid is seen from the side, and is made up of platforms. Platforms are impassable cells.
The player controls a character. On each turn the character can move in any of the cardinal directions except the one it just came from.
Each turn of movement consumes one unit of jetpack charge. When the character stands on a platform, the jetpack instantly recharges fully. If the jetpack charge reaches zero, however, the character is removed from the game.
The amount of the "full charge" of the jetpack is a parameter of the game at this point.
With a little effort, one can see that a "character-with-a-jetpack" who follows the head of a snakebot is equivalent to the whole snakebot. In other words, the exact shape of the snakebot does not matter, the only thing that matters is the segment of the snakebot that is supported by a platform - and about that all I want to know is how far away it is from the tail of the snake.
Approximation
The snakebots in the actual CodinGame challenge differ from the snakebots in the above "Projection" section. The main difference is that they cannot pass through themselves. (Other differences, like the ability to fall down I consider less significant). However, most of the time, the snake is not even trying to pass through itself – so, maybe, we can use the "transparent" snake from the prevois section for most of our optimal control problem?
Mathematically, we again have two optimal control problems: 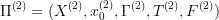 and
and 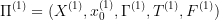 . We say that
. We say that 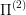 is approximated by
is approximated by 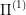 if
if
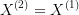 ,
, 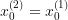 ,
, 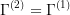
- and there is a "small" set
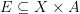 such that
such that
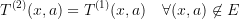
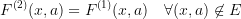
The definition is symmetric, but here presumably 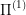 is "easier to solve" and
is "easier to solve" and 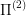 is the problem we are actually interested in.
is the problem we are actually interested in.
The difficulty here is that even if the set of exceptions 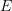 is small, it has the potential to affect the value function and the optimal controls for states far away from
is small, it has the potential to affect the value function and the optimal controls for states far away from 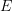 . We cannot write
. We cannot write
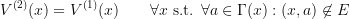
So what can we do?
Final part of the optimal path is easy under some conditions
In the example with a snakebot approximated by a "transparent" snakebot, controlling the "real" snakebot is always harder than controlling the "transparent" one:
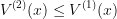 by induction.
by induction.
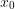 we find an optimal control
we find an optimal control 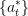 for
for 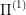 such that the whole optimal trajectory is non-exceptional
such that the whole optimal trajectory is non-exceptional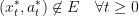
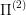 and
and 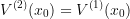 and
and 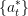 is optimal for
is optimal for 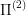 .
.
If our starting state does not have this property, we can build our decision tree as usual for an optimal control problem until we do hit a state with this property. From that point on we don't need to keep solving the full problem 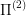 but can reuse the solution to the (presumably easier)
but can reuse the solution to the (presumably easier) 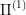 instead.
instead.
Maybe subregions of state-space can be reused?
The next best thing I can think of (and I'm not sure if this idea works) is to identify subregions of the state-space where we could reuse the solution approaches to 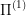 though not
though not 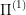 itself. So, let's say we identify a subset
itself. So, let's say we identify a subset 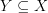 and we formulate an optimal control problem
and we formulate an optimal control problem 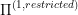 such that
such that
- the state space
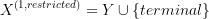
- transition function
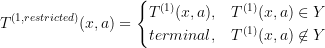
- reward function
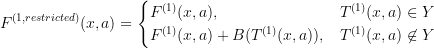
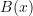 is a boundary condition reward: ideally,
is a boundary condition reward: ideally, 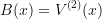 but we would need to solve for that somehow.
but we would need to solve for that somehow.
In other words, 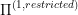 is the same as
is the same as 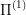 as long as we are inside the region
as long as we are inside the region 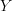 , and once we leave
, and once we leave 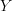 we assign ourselves a reward
we assign ourselves a reward 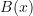 depending on our final state
depending on our final state  . I visualise
. I visualise 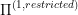 as the problem of navigating a snakebot inside a room in our snakebot example.
as the problem of navigating a snakebot inside a room in our snakebot example.
Now, assuming that we can solve 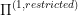 using the same methods as solving
using the same methods as solving 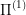 (or using some other methods that make it easier than
(or using some other methods that make it easier than 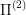 ) and assuming that the optimal trajectory is non-exceptional (does not include state-control pairs from the set
) and assuming that the optimal trajectory is non-exceptional (does not include state-control pairs from the set 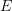 ), and also that we still have the relation
), and also that we still have the relation 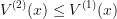 , then we can reuse the optimal trajectories from
, then we can reuse the optimal trajectories from 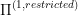 for our controls within region
for our controls within region 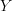 .
.
In a sense, traversing 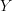 becomes a single step in our optimal control problem: tell me where you want to exit
becomes a single step in our optimal control problem: tell me where you want to exit 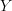 and I will tell you the optimal control and the cumulative reward of (optimally) getting there through
and I will tell you the optimal control and the cumulative reward of (optimally) getting there through 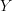 .
.
Diversity of paths matters, but how?
For snakebots, it is not unusual that there are multiple optimal or close-to-optimal ways to get from state 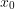 to a desired state
to a desired state 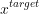 . Intuitively, the more ways there are for problem
. Intuitively, the more ways there are for problem 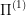 to navigate from
to navigate from 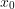 to
to 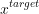 , the more likely is that one of those ways will be suitable for
, the more likely is that one of those ways will be suitable for 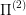 . Is there some way to formalize and use this fact to actually solve
. Is there some way to formalize and use this fact to actually solve 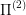 ? I don't know.
? I don't know.
How do navigation apps do it?
When I ask OsmAnd for public-transport navigation between cities, it often chokes – presumable on the amount of options for getting around. Yet, for a human, the navigation is not hard in this case: find a train that goes from one city to the other, then find a way to get to and from the train stations. This is similar to the "subregion" approach I discuss above – I am sure that apps like OsmAnd already use it. How do they implement it?
In place of conclusion
When starting this blog, I promised that I will have more questions than answers. Here we go.